Atualmente, algo muito comum é o uso do Entity Framework ou de outros ORMs para facilitar o acesso a dados e acelerar o desenvolvimento. Mas, algo que muitas vezes acaba se tornando uma grande dor de cabeça é saber qual consulta o Entity Framework está montando para realizar junto ao banco de dados.
Quando a consulta envolve muitas cláusulas ou várias tabelas (ou, por vezes, as duas coisas) e o resultado não é o esperado, o que acaba acontecendo é que gastamos muito tempo para entender o motivo do erro.
Sem dúvidas esse tempo seria muito menor se soubessemos qual consulta está sendo realizada, e é exatamente esse ponto que pretendo cobrir nesse artigo.
Para isso, vou montar um exemplo funcional com uma base de dados MySQL rodando em Docker, uma API usando Serilog e, claro, o Entity Framework. O objetivo aqui não é se aprofundar em nenhuma dessas tecnologias, mas, para chegar ao nosso destino temos que passar por elas. Dúvidas adicionais sobre qualquer um desses pontos posso responder nos comentários e quem sabe falar sobre esses itens no futuro.
Se você não quiser ler sobre o Docker, MySQL e o Serilog pode ir diretamente para o último bloco do post “Logando queries do EF com Serilog”.
Se você chegou aqui de outro artigo para ler Docker clique aqui.
Se você chegou aqui de outro artigo para ler sobre MySQL clique aqui.
Docker
Docker foi concebido com a ideia de facilitar a publicação e execução de aplicações usando containers. O container permite que o desenvolvedor crie um pacote de sua aplicação com apenas o que é necessário. Isso é possível, pois, a mágica do Docker é permitir que essas aplicações, cada uma em seu container use o mesmo kernel do Linux em que estão rodando, portanto, quando o desenvolvedor cria um pacote de sua aplicação, esse pacote só está levando a aplicação e suas dependências, que não existem na máquina hospedeira. Com isso fica claro que o Docker e seus containers não são máquinas virtuais.
“Mas, Luizão, por que vamos usar Docker pra rodar o MySQL? Não posso instalar o MySQL direto na minha máquina e vai dar no mesmo?”
Sim, pode instalar direto na sua máquina, e sim vai dar no mesmo. Gosto de rodar o MySQL no Docker, pois, não preciso dele instalado na minha máquina e quando termino de testar ou desenvolver o que quero desligo o container e não tenho mais o MySQL rodando nem os dados que estavam armazenados nele, ou seja, fiz tudo o que precisava sem ter que instalar mais uma ferramenta e sem afetar meu ambiente. O mesmo se aplica a qualquer outra ferramenta que você venha a rodar através de container, já precisei de várias coisas além do MySQL e simplesmente baixei a imagem do container, rodei local, fiz o que precisava e joguei fora. Simples assim!
Para instalação do Docker Desktop só precisamos baixar seu instalador e seguir a instalação padrão. Recomendo baixar diretamente no DockerHub e o link para a página de download é esse aqui.
MySQL
Agora que já temos o Docker devidamente instalado vamos ao MySQL.
Para baixar a imagem do MySQL e subir o container basta abrir um terminal (bom e velho CMD ou outro de sua preferência, eu uso o cmder) e executar o seguinte comando:
docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=password -d mysqlNossos parâmetros querem dizer o seguinte:
- -p irá redirecionar a porta 3306 do container para a porta 3306 de nossa máquina, vamos nos comunicar com o banco por ela.
- -e é utilizado para atribuir as variáveis de ambiente do container, aqui estou dizendo que minha senha de root é 'password'.
- -d é para subir o container de forma a não prender nosso terminal, ele subirá o container e retornará ao terminal.
Para mais detalhes e sobre os possíveis parâmetros do docker run você poder dar uma olhada na documentação deles aqui.
E para mais detalhes sobre as variáveis de ambiente, configurações e a imagem do MySQL em si pode dar uma olhada aqui.
Agora ao executarmos o comando:
docker psVeremos nosso container de pé:

MySQL Workbench
Precisamos de alguma ferramenta pra nos conectarmos com nossa base de dados, para o MySQL eu uso o MySQL Workbench, você pode baixar ela aqui. Lembrando que se tiver alguma outra ferramenta de sua preferência pode ficar à vontade.
Depois de seguir a instalação padrão do MySQL Workbench vamos nos conectar com nossa base.
Primeiro abrimos o MySQL Workbench.
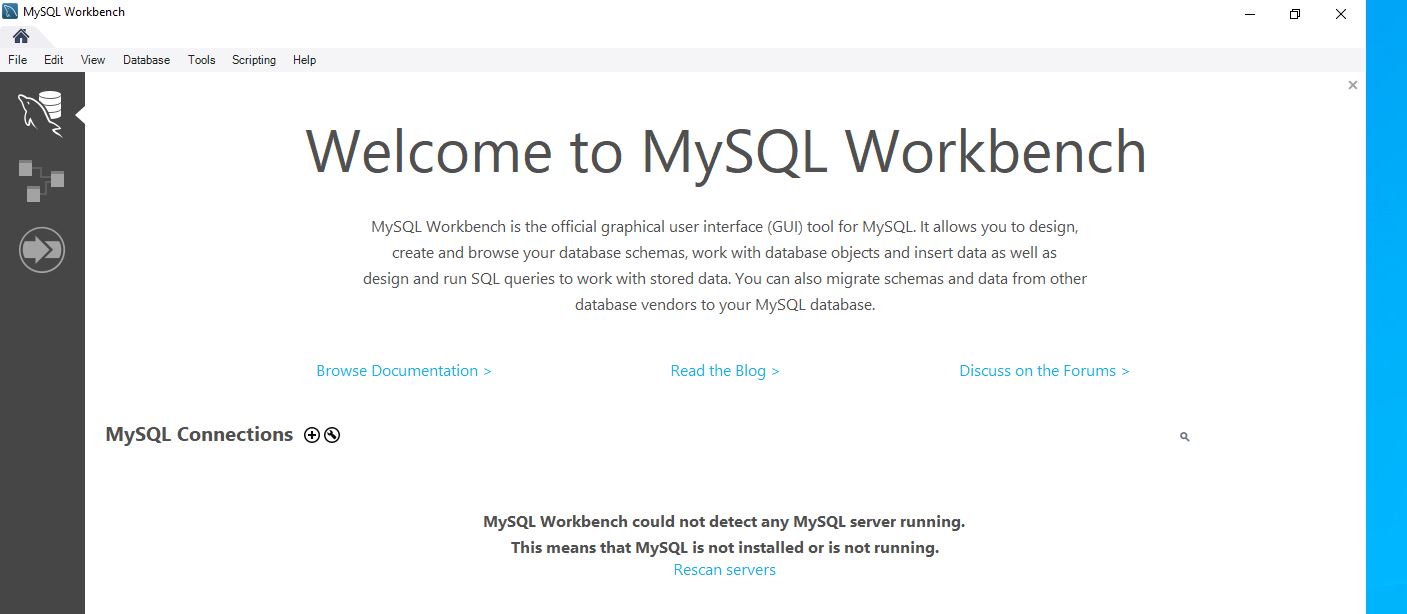
Agora vamos em ‘MySQL Connections’ e clicamos no ícone de ‘+’ para adicionar uma nova conexão.
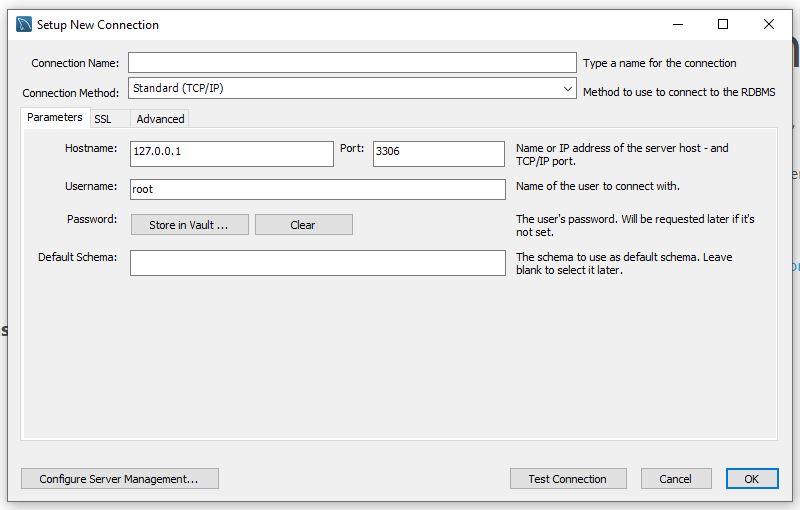
E preenchemos com as informações de nosso servidor recém criado. As informações já virão como precisamos, ‘Hostname’ como localhost (127.0.0.1), ‘Port’ com a porta padrão do MySQL que é a 3306 (lembra que redirecionamos quando subimos o container?) e o ‘Username’ já virá como ‘root’, então clicamos em ‘Store in Vault …’ para adicionar a nossa senha:
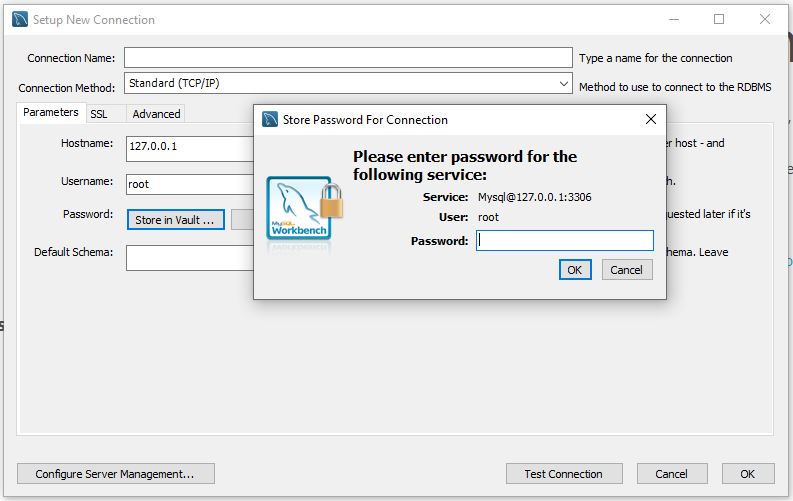
Depois de ter inserido a senha basta clicarmos em ‘OK’ e em seguida ‘Test Connection’. Se tudo correu bem teremos uma tela como essa:
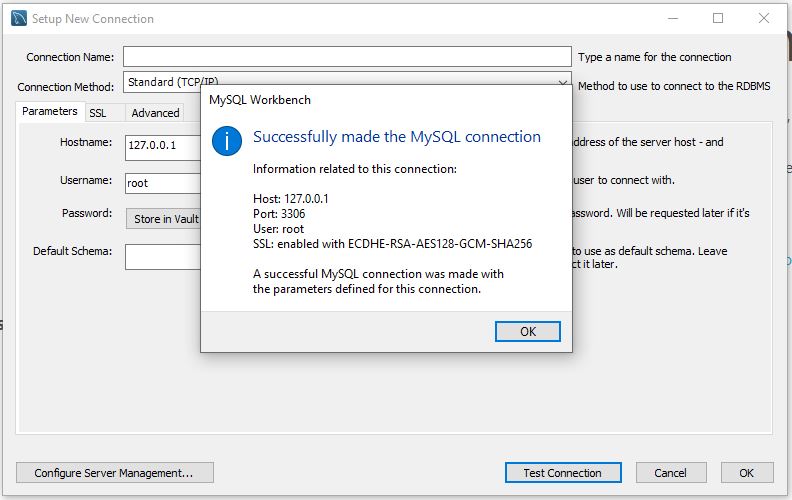
Agora basta dar um nome para nossa conexão e clicar em ‘OK’, a conexão aparecerá no painel inicial e ficará salva para facilitar futuros acessos:
Clicando na conexão já seremos redirecionados para uma tela com um editor SQL e já podemos usar!
Para nosso exemplo vou criar uma estrutura de dados simples com 3 tabelas só para termos alguns joins e chegarmos ao nosso objetivo de estudo. Vamos criar uma API para listar as notas dos alunos em determinadas disciplinas. Uma tabela com as disciplinas, uma com os alunos, e uma relacionando alunos com as disciplinas contendo as notas.
Vamos ao editor SQL e criar nossas estruturas, primeiro o schema, vou chamar ‘grades’ e em seguida vou criar as tabelas:
create schema grades;
use grades;
create table student(
id int primary key auto_increment,
`name` varchar(100) not null
);
create table `subject`(
id int primary key auto_increment,
`name` varchar(100) not null
);
create table student_grade(
id int primary key auto_increment,
student_id int not null,
subject_id int not null,
grade decimal(3, 2) not null,
foreign key (student_id) references student(id),
foreign key (subject_id) references `subject`(id)
);Com esse script no SQL Editor basta clicar no ícone com um raio na própria aba de edição ou pressionar Ctrl + Shift + Enter para executar todo o script. Se correr tudo bem devemos ter uma saída como essa:

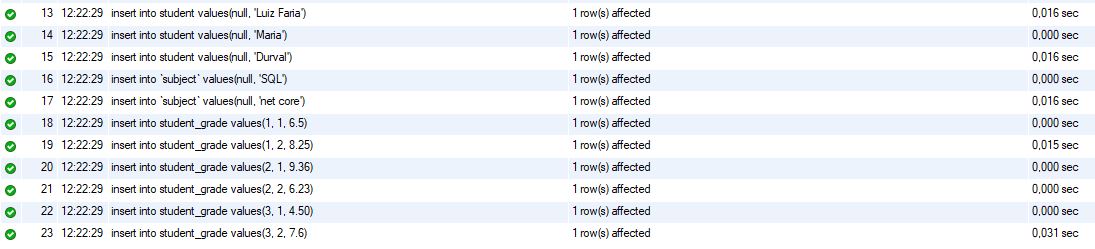
Estruturas criadas, vamos inserir alguns dados para termos o que pesquisar em nossa API:
insert into student values(null, 'Luiz Faria');
insert into student values(null, 'Maria');
insert into student values(null, 'Durval');
insert into `subject` values(null, 'SQL');
insert into `subject` values(null, 'net core');
insert into student_grade values(null, 1, 1, 6.5);
insert into student_grade values(null, 1, 2, 8.25);
insert into student_grade values(null, 2, 1, 9.36);
insert into student_grade values(null, 2, 2, 6.23);
insert into student_grade values(null, 3, 1, 4.50);
insert into student_grade values(null, 3, 2, 7.6);Se tudo correu conforme o esperado, teremos a seguinte saída:
Agora vamos voltar nossas atenções para nossa API.
API
Criei um projeto de Aplicativo Web ASP.NET Core e usei o template de API.
Vamos começar com nossas entidades que deverão refletir as estruturas que criamos no banco, criei cada uma em um arquivo, mas, vou colocá-las juntas aqui para facilitar a leitura:
public class Student
{
public int Id { get; set; }
public string Name { get; set; }
public List<Grade> Grades { get; set; }
}
public class Subject
{
public int Id { get; set; }
public string Name { get; set; }
}
public class Grade
{
public int Id { get; set; }
public int StudentId { get; set; }
public Student Student { get; set; }
public int SubjectId { get; set; }
public Subject Subject { get; set; }
public float Value { get; set; }
}Feito isso, vamos criar nosso contexto com o Entity Framework, uma classe GradesContext.cs com o seguinte conteúdo:
public class GradesContext : DbContext
{
public GradesContext(DbContextOptions options) : base(options)
{
}
public DbSet<Student> Students { get; set; }
public DbSet<Subject> Subjects { get; set; }
public DbSet<Grade> Grades { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.HasDefaultSchema("grades");
modelBuilder.Entity<Student>().ToTable("student");
modelBuilder.Entity<Student>().HasKey("Id");
modelBuilder.Entity<Student>().Property("Name").HasColumnName("name");
modelBuilder.Entity<Subject>().ToTable("subject");
modelBuilder.Entity<Subject>().HasKey("Id");
modelBuilder.Entity<Subject>().Property("Name").HasColumnName("name");
modelBuilder.Entity<Grade>().ToTable("student_grade");
modelBuilder.Entity<Grade>().HasKey("Id");
modelBuilder.Entity<Grade>().Property("StudentId").HasColumnName("student_id");
modelBuilder.Entity<Grade>().Property("SubjectId").HasColumnName("subject_id");
modelBuilder.Entity<Grade>().Property("Value").HasColumnName("grade");
}
}E vamos criar nosso método para listar todas as notas de todos os alunos, para isso, criei uma classe GradeRepository.cs com o seguinte código:
public class GradeRepository
{
private readonly GradesContext _gradesContext;
public GradeRepository(GradesContext gradesContext)
{
_gradesContext = gradesContext;
}
public Task<List<Student>> FindGrades()
{
var result = _gradesContext
.Students
.Include(student => student.Grades)
.ThenInclude(grade => grade.Subject)
.AsNoTracking()
.ToList();
return Task.FromResult(result);
}
}Agora vamos para a controller, um simples GET vai resolver nosso problema:
public class GradesController : ControllerBase
{
private readonly GradeRepository _gradeRepository;
public GradesController(GradeRepository gradeRepository)
{
_gradeRepository = gradeRepository;
}
[HttpGet]
public async Task<IActionResult> FindGradesAsync()
{
var result = await _gradeRepository.FindGrades();
return Ok(result);
}
}E finalmente vamos amarrar tudo isso na Startup.cs:
public void ConfigureServices(IServiceCollection services)
{
//Injetando o DbContext com a connection string
services.AddDbContext<GradesContext>(options => options.UseMySql("Server=localhost;Database=grades;Uid=root;Pwd=password;"), ServiceLifetime.Transient);
//Injetando o GradeRepository
services.AddTransient<GradeRepository>();
services.AddControllers();
}Tudo pronto, vamos executar nosso projeto!
Quando chamarmos a nossa controller deveremos ter como retorno nossa lista de alunos com suas notas:
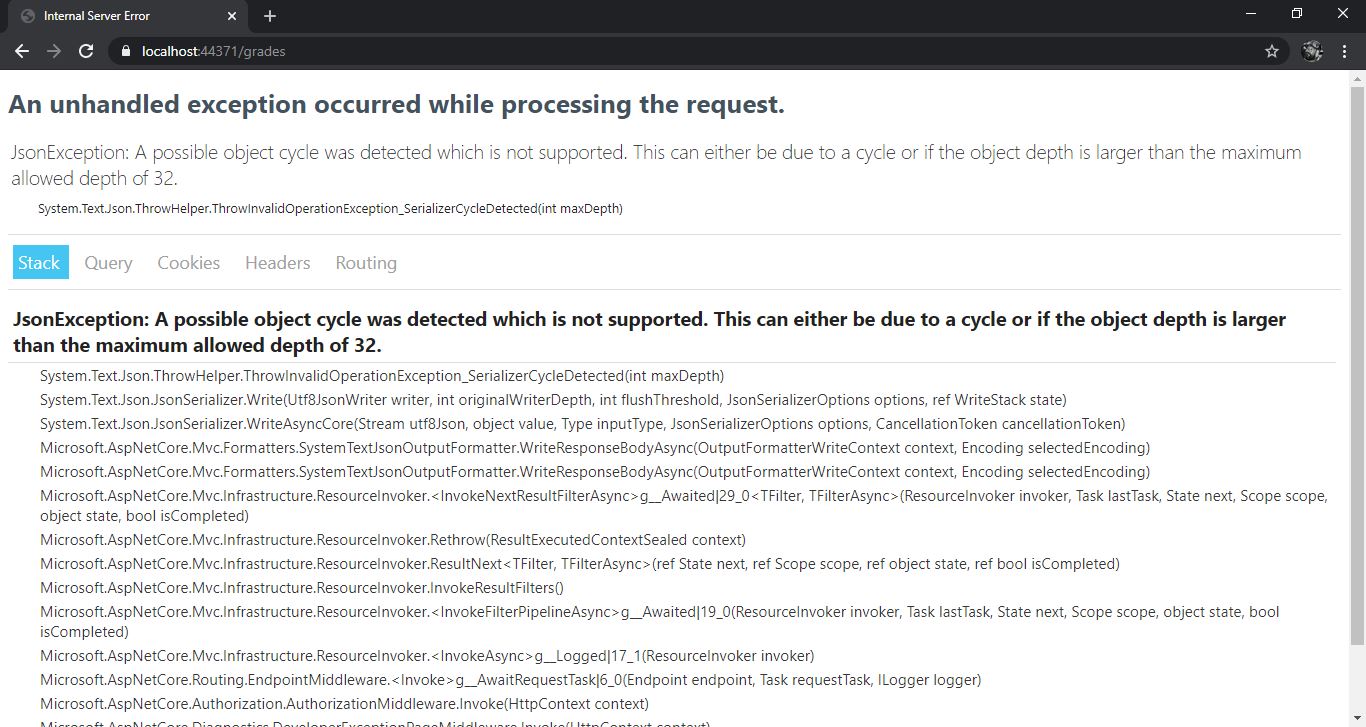
E recebemos esse erro. Esse erro se dá pois nosso alunos (Student) possuem uma lista de notas (Grade) e nosso objeto que trafega as notas (Grade) possui um objeto de aluno (Student) que possui notas (Grade) e acho que você já entendeu e eu poderia ficar aqui até amanhã nesse ciclo…
A primeira pergunta que pode lhe ocorrer é “por que temos esse objeto ali se está nos causando problemas?” e a resposta é simples, como as notas são de um estudante faz sentido eu poder a partir de uma nota chegar ao estudante ‘dono’ da nota. E a segunda pergunta é “como resolvemos isso?” e a resposta é igualmente simples, basta adicionarmos o atributo JsonIgnore na classe ‘Grade’, conforme exemplo abaixo:
public class Grade
{
public int Id { get; set; }
public int StudentId { get; set; }
[JsonIgnore]
public Student Student { get; set; }
public int SubjectId { get; set; }
public Subject Subject { get; set; }
public float Value { get; set; }
}Esse atributo simplesmente impede que o conteúdo da classe Student dentro de Grade seja serializado. Existem outras formas de resolver esse tipo de problema e essa atende mais especificamente nosso caso já que vamos listar as notas dos alunos e, portanto, já sei de quem é a nota. Deixei o problema ocorrer com fins didáticos para poder demonstrar a solução e para que fiquem claros os perigos de lidar com esse tipo de relacionamento.
Com o código corrigido, vamos rodar novamente:

Agora recebemos o retorno esperado, um json com todas as notas de todos os alunos.
Mas, nosso objetivo aqui é fazer o Entity Framework logar suas queries no Serilog então vamos lá.
Serilog
Serilog é uma biblioteca que tem como objetivo prover um mecanismo de log que seja capaz de escrever em diversos tipos de saída, como console, arquivos, banco de dados, Microsoft Teams e mais vários outros. Depois que você baixa o pacote do Serilog basta adicionar os Sinks para escrever esse registro de log para a saída que desejar. Sinks funcionam como plug-ins que incrementam as funcionalidades do Serilog. Mais informações podem ser encontradas no próprio site do Serilog.
Primeiro vamos adicionar os pacotes NuGet do Serilog que vamos usar. Vamos precisar dos seguintes pacotes:
- Serilog - É o cerne do funcionamento do Serilog, o pacote base para realizar qualquer tipo de registro de log.
- Serilog.Sinks.Debug - Sink responsável por escrever os registros do Serilog no debug console do Visual Studio.
- Serilog.Sinks.File - Sink responsável por escrever os registro do Serilog em arquivos de texto.
- Serilog.Extensions.Logging - Extensão que utilizaremos para rotear as mensagens de log do sistema de log do ASP.NET Core para o Serilog.
Agora, vamos às alterações em nosso código.
Logando queries do EF com Serilog
Primeiramente, precisamos das seguintes configurações no Startup.cs:
public void ConfigureServices(IServiceCollection services)
{
//Configurando o Serilog
Log.Logger = new LoggerConfiguration()
.WriteTo.Debug() //Para escrever registros para o janela de degub do Visual Studio
.WriteTo.File("log.txt") //Para escrever registros de log em um arquivo de texto
.CreateLogger();
services.AddLogging(); //Adiciona o LoggerFactory aos serviços
//Injetando o DbContext com a connection string
services.AddDbContext<GradesContext>(options => options.UseMySql("Server=localhost;Database=grades;Uid=root;Pwd=password;"), ServiceLifetime.Transient);
//Injetando o GradeRepository
services.AddTransient<GradeRepository>();
services.AddControllers();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env, ILoggerFactory loggerFactory)
{
//Adicionando o serilog ao fluxo de log do ASP.NET Core
loggerFactory.AddSerilog();
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}Agora, vamos alterar o GradesContext.cs, primeiramente, vamos mudar o construtor para receber o LoggerFactory que passamos a injetar no Startup e uma propriedade pra armazená-lo:
private readonly ILoggerFactory _loggerFactory;
public GradesContext(DbContextOptions options, ILoggerFactory loggerFactory) : base(options)
{
_loggerFactory = loggerFactory;
}E vamos sobrecarregar o método OnConfiguring para configurar o log:
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseLoggerFactory(_loggerFactory);
}Agora, quando executarmos a mesma rota de antes deveremos encontrar algum registro como esse na janela de debug do Visual Studio:

Olhando o arquivo de log que configuramos deveremos encontrar exatamente a mesma saída:

E o melhor de tudo é que se pegarmos essa query e executarmos no MySQL teremos o resultado que originou o retorno que tivemos de nosso GET.
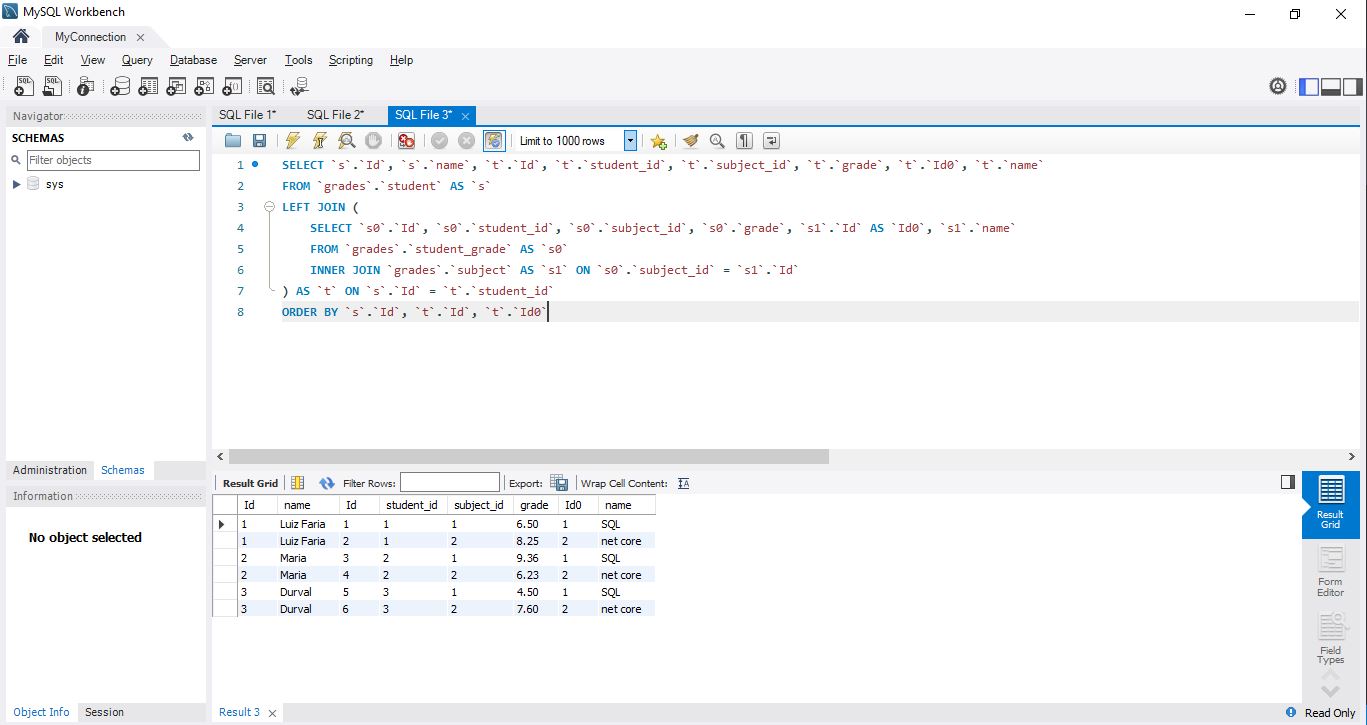
Agora, vamos criar mais dois métodos em nosso GradeRepository com buscas mais complexas:
public Task<List<Student>> FindGrades(string studentName)
{
var result = _gradesContext
.Students
.Where(s => s.Name.Equals(studentName))
.Include(student => student.Grades)
.ThenInclude(grade => grade.Subject)
.AsNoTracking()
.ToList();
return Task.FromResult(result);
}
public Task<List<Student>> FindGrades(string studentName, string subjectName)
{
var result = _gradesContext
.Students
.Where(s => s.Name.Equals(studentName))
.Include(student => student.Grades)
.ThenInclude(grade => grade.Subject)
.Select(item => new Student
{
Name = item.Name,
Id = item.Id,
Grades = item.Grades.Where(gradeItem => gradeItem.Subject.Name.Equals(subjectName)).ToList()
})
.AsNoTracking()
.ToList();
return Task.FromResult(result);
}E vamos adicionar novas actions na Controller:
[HttpGet("{studentName}")]
public async Task<IActionResult> FindGradesAsync([FromRoute]string studentName)
{
var result = await _gradeRepository.FindGrades(studentName);
return Ok(result);
}
[HttpGet("{studentName}/{subject}")]
public async Task<IActionResult> FindGradesAsync([FromRoute]string studentName, [FromRoute]string subject)
{
var result = await _gradeRepository.FindGrades(studentName, subject);
return Ok(result);
}Basicamente adicionei mais duas possibilidades de busca, por aluno e por aluno e disciplina. A ideia é termos algumas consultas um pouco mais complexas para podermos analisar suas saídas.
Agora, vamos chamar nossa rota grades/luiz faria e analisar a query gerada pelo Entity Framework:
SELECT `s`.`Id`, `s`.`name`, `t`.`Id`, `t`.`student_id`, `t`.`subject_id`, `t`.`grade`, `t`.`Id0`, `t`.`name`
FROM `grades`.`student` AS `s`
LEFT JOIN (
SELECT `s0`.`Id`, `s0`.`student_id`, `s0`.`subject_id`, `s0`.`grade`, `s1`.`Id` AS `Id0`, `s1`.`name`
FROM `grades`.`student_grade` AS `s0`
INNER JOIN `grades`.`subject` AS `s1` ON `s0`.`subject_id` = `s1`.`Id`
) AS `t` ON `s`.`Id` = `t`.`student_id`
WHERE `s`.`name` = @__studentName_0
ORDER BY `s`.`Id`, `t`.`Id`, `t`.`Id0`Já podemos perceber a adição do parâmetro ‘__studentName_0’ em sua consulta. Agora vamos executar a rota grades/luiz faria/sql:
SELECT `s`.`name`, `s`.`Id`, `t`.`Id`, `t`.`student_id`, `t`.`subject_id`, `t`.`grade`, `t`.`Id0`, `t`.`name`
FROM `grades`.`student` AS `s`
LEFT JOIN (
SELECT `s0`.`Id`, `s0`.`student_id`, `s0`.`subject_id`, `s0`.`grade`, `s1`.`Id` AS `Id0`, `s1`.`name`
FROM `grades`.`student_grade` AS `s0`
INNER JOIN `grades`.`subject` AS `s1` ON `s0`.`subject_id` = `s1`.`Id`
WHERE `s1`.`name` = @__subjectName_1
) AS `t` ON `s`.`Id` = `t`.`student_id`
WHERE `s`.`name` = @__studentName_0
ORDER BY `s`.`Id`, `t`.`Id`, `t`.`Id0`Agora, percebemos a adição de mais um parâmetro, a disciplina como ‘__subjectName_1’. E mais uma vez, se pegarmos essas consultas e executarmos no MySQL Workbench substituindo esses parâmetros gerados pelo Entity Framework por aqueles que passamos na rota, teremos exatamente os mesmos resultados:
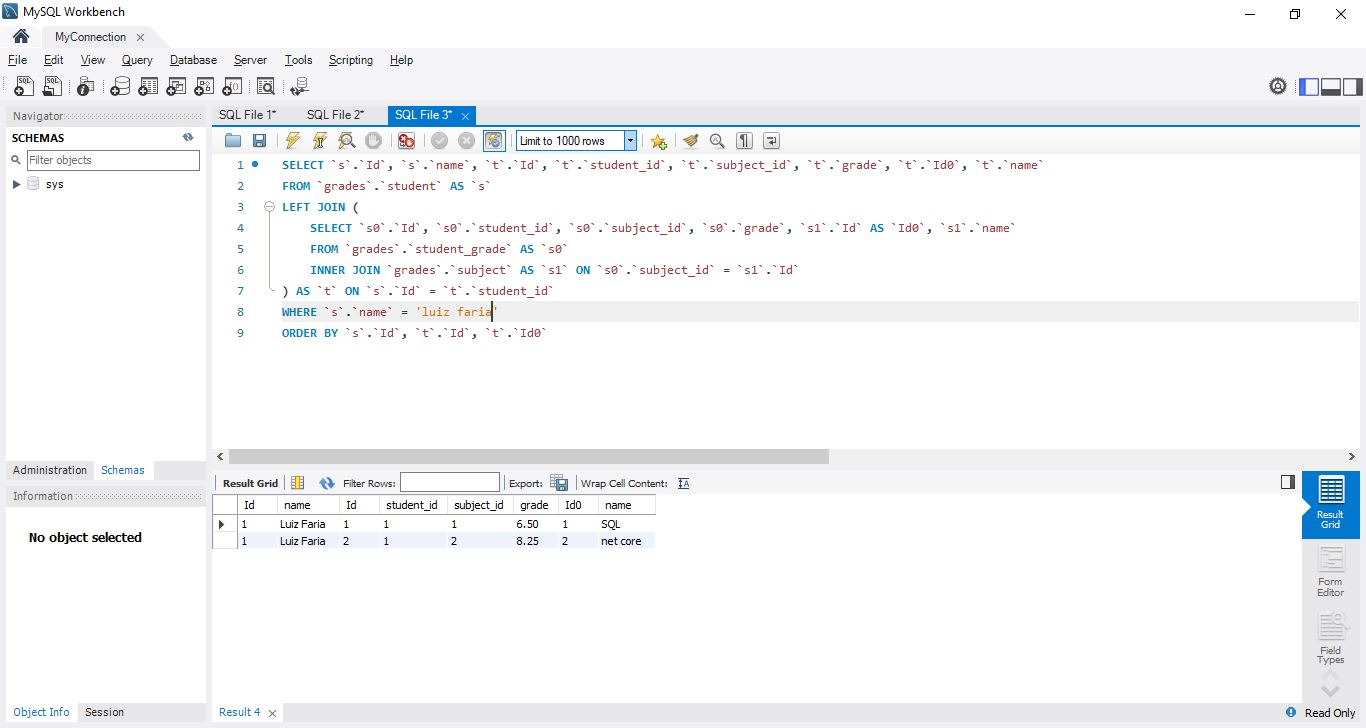
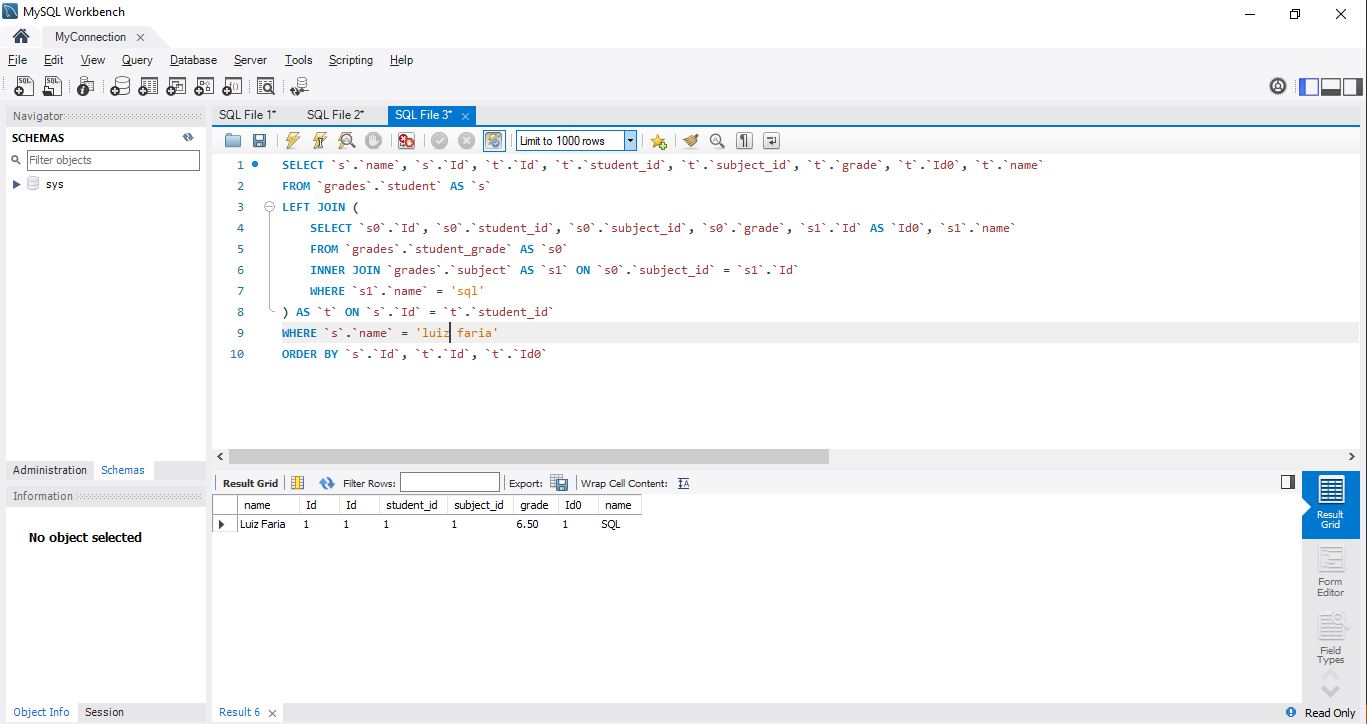
Conclusão
Com essas simples saídas geradas pelo Entity Framework podemos perceber como nossa vida pode ser facilitada por termos em mãos as queries geradas por ele quando o resultado de nossas consultas não é o esperado. Nossa estrutura de dados é muito simples, mas, imaginem um cenário com muitas outras tabelas e muitas outras cláusulas. Imaginem o quão difícil pode ser encontrar o problema.
Todo o código está no meu git.
Espero que tenha sido útil e até a próxima!
Esse post foi útil pra você?